리스트란?
데이터를 순서대로 나열한 자료구조이다. (스택과 큐 구조도 리스트 구조로 되어 있다.)
선형 구조를 갖는 리스트에는 선형 리스트와 연결리스트가 있다.
선형 리스트는 데이터가 배열처럼 연속하는 메모리 공간에 저장되어 순서를 갖고있다.
연결리스트는 데이터가 메모리 공간에 연속적으로 저장되어 있지 않더라도 각각의 데이터 안에 다음 데이터에 대한 정보를 갖고 있어 서로 연결된다.
배열의 시간복잡도를 생각해보면, 중간 삽입과 삭제의 시간복잡도가 O(N)이었다.
O(1)과 O(N)의 효율은 차이가 많고, 삽입과 삭제를 매우 자주해야 하는 상황에선 배열보다 연결 리스트가 효율적일 수 있다.
하지만, 연결리스트는 탐색이 O(N)으로 느린 반면 삽입과 삭제는 O(1)로 매우 빠르기 때문에 삽입과 삭제가 잦은 상황에서 자주 사용된다.
연결리스트(Linked List)
- 데이터를 담고 있는 노드의 연결관계로 구성된 자료구조,
- 삭제와 삽입에 최적화된 구로조, 각각 O(1)의 시간복잡도를 갖고 있다.

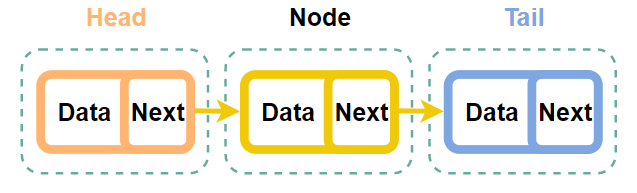
연결 리스트는 노드라는 개념이 있고 노드는 정보를 담는 하나의 창구로 보면 된다.
일반적으로 연결 리스트에서 하나의 노드는 데이터와 다른 노드로 이동하는 경로를 갖고 있다.
연결 리스트는 여러개의 노드가 모여서 형성되는 구조이다.
단일 연결리스트
연결 리스트란 노드가 여러개 모여서 만들어지는 하나의 구조이다. 단일은 연결 방향이 단방향이다. 마치 일방통행 같은 구조이다. 노드는 데이터와 다른 노드의 참조를 갖고 있고, 단일 연결 리스트의 노드가 갖고 있는 다른 노드의 참조란 진행방향으로 이었을 때의 바로 옆 노드를 말하는 것이다.
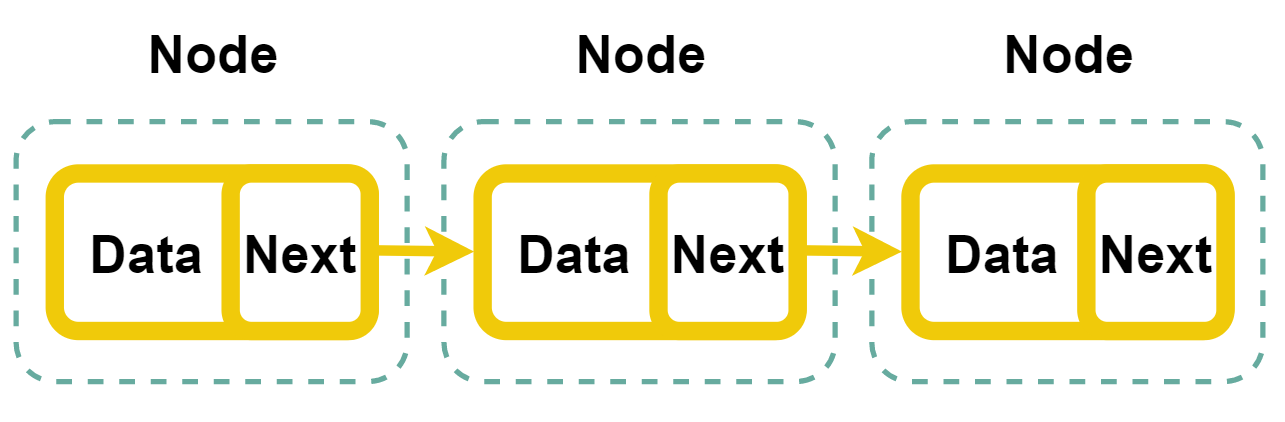
각 노드별로 data와 next값을 가지고 있는데 Data는 값을 Next는 그 다음 노드의 위치를 가리키는 역할을 한다.
만약 3의 data를 가진 노드가 하나 있는데, 다음 노드가 없다면 Next에는 기본적으로 비어있다는 뜻으로 null이 들어가게된다. 이것을 수도 코드로 나타내면 다음과 같다.
// 노드를 만드는 수도코드
set node1 = node()
node1.data = 3이 노드 바로 뒤에, 값이 5인 노드를 추가적으로 만들어 연결지어 보면
먼저 값이 5인 노드를 새로 만들어주고, node2 변수에 할당한다.
그 다음 node1 뒤에 node2를 연결해야 하므로, node1.next를 node2로 설정해준다.
새로운 노드 node2를 만들어, node1 뒤에 연결하는 수도 코드는 다음과 같이 작성해볼 수 있다.
set node2 = node(5)
node1.next = node2
node1.next라는 것은 바로 node2 자체를 의미하게된다.
연결되어 있는 node1, node2를 다시 분리 시키는 작업은
바로 node1.next 값에 null을 넣어주면 된다.
set node1 = node(3)
set node2 = node(5)
node1.next = node2
print(node1.next.data) # 5
node1.next = null # 두 관계를 끊어줍니다.이렇게 next값에 null 넣어주는 것은 뒤에서 노드를 삭제할 때 이용하게 된다.
하지만, 위와 같은 형태에서 끝내면 시작점을 찾을 수 없고 리스트의 모든 값을 탐색해야 하는 상황이 발생했을때 문제가 생긴다. 시작점을 알 수 없다면 모든 값을 탐색했는지 판단 할 수가 없다.
따라서 리스트의 첫번째 값의 위치를 반드시 명시해야하며, 이것을 head라고 부른다.
더불어, 종료되는 지점도 있어야한다. 종료지점을 명시해놓으면 탐색할 때 추가적인 처리 없이 현재 방문한 노드가 종료 지점인지 판단하는 과정만 거쳐서 탐색을 종료할 수 있을 것입니다.

이렇게 head와 Tail까지 만들어 구성해 놓으면, 배열과 마찬가지로 삽입, 삭제, 탐색이 모두 가능한 자료구조가 된다.
탐색은 Head부터 Tail까지 일일이 확인해야해서 O(N)이라는 시간이 소요되지만,
이때 단일 연결 리스트에서는 삽입, 삭제의 경우 인접한 곳의 선을 끊고 연결해주는 작업만 해주면 되므로 O(1) 이라는 시간이 소요된다. 단, 일방향으로만 진행되기 때문에 뒤로 돌아갈 수 없는 구조이다.
단일 연결 리스트 - 삽입/삭제/탐색
단일 연결 리스트도 배열에서 처럼 삽입/삭제/탐색 연산을 수행해야 할일이 있다.
특히 연결리스트는 삽입과 삭제 연산에 최적화 된 자료구조이다.
삽입
ⓐtail 뒤쪽에 값을 삽입
tail은 next가 비어있기 때문에, 새로운 노드가 들어오게 된다면 next가 가리키는 노드를 해당 노드로 지정해주면 간단하게 연결처리가 된다. 새로운 노드는 현재 tail보다 뒤쪽에 위치할 것이기 때문에, 추가적으로 tail이 가리키는 노드도 변경 해줘야한다.
Step1. 노드 만들기

Step2. 이어 붙이기

Step3. Tail 변경하기
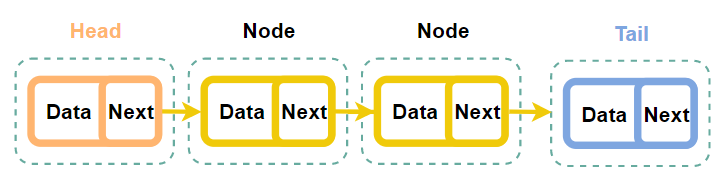
노드를 만들고 이어 붙인 후 tail을 옮기는 작업을 해주어야한다. 이 과정을 수도코드로 옮기면 다음과 같다.
function SLL.insert_end(num)
set new_node = node(num) # Step 1. 노드 만들기
SLL.tail.next = new_node # Step 2. 이어 붙이기
SLL.tail = new_node # Step 3. Tail 변경하기ⓑ head 바로 뒤에 노드를 추가
head의 뒤쪽으로 추가할때 연결을 그냥 끊어버리게 되면 예상치 못한 결과가 나올 수 있다.
- 새로운 노드(New Node)를 만들어 준다.
- 새로운 노드의 next 값을, head의 next값으로 설정해준다.
- head의 next 값을 새로운 노드로 변경한다
위의 작업을 순서대로 하여 head 바로 뒤에 새로운 노드를 추가할 수 있다.
function SLL.insert_after_head(num)
set new_node = node(num) # Step 1. 노드 만들기
new_node.next = SLL.head.next # Step 2. 새로운 노드의 next 값 변경
SLL.head.next = new_node # Step 3. Head의 next 값 변경삭제
삭제는 삽입과 유사하다. 삽입할때는 연결을 새로 정의해야 했지만, 삭제는 연결을 제거하면 된다.
삭제시 삭제할 노드의 바로 전 노드에서 그 다음 노드로 연결관계를 바꿔줘야 한다.
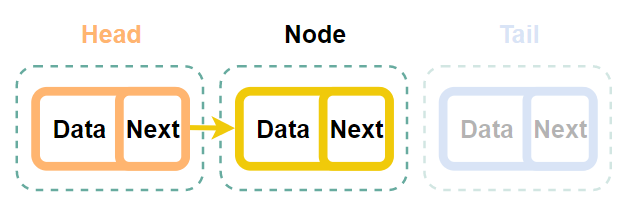
ⓐtail을 삭제하는 과정
바로 tail의 전 노드의 next 값을 null로 바꾸고 tail을 그 전으로 옮겨주면 된다.
Step 0. 초기상태
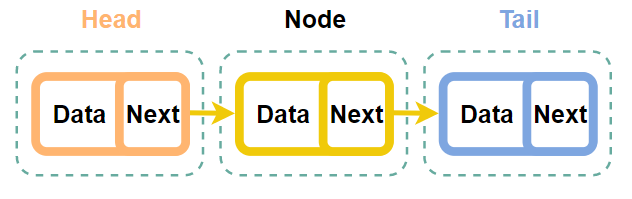
Step 1. Tail 바로 전 노드의 next를 null로 설정
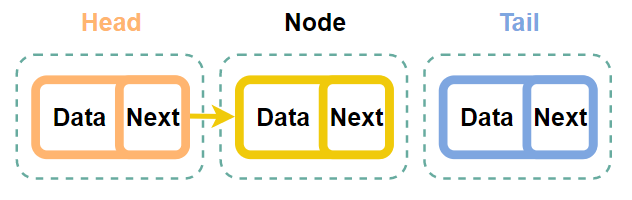
Step 2. Tail 변경하기
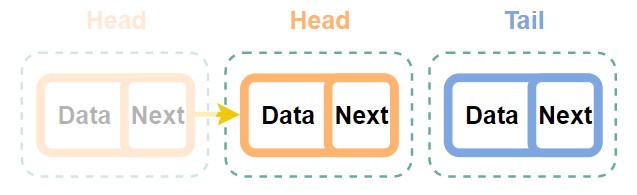
ⓑhead 삭제하는 과정
head의 값을 head.next로 지정하면 된다. 이건 실제로 값을 삭제하는 것은 아니지만 head.next로 정의하게 되면 참조하는 head값은 그 다음 값이기 때문에 노드가 정상적으로 삭제된 것처럼 보여준다.
Step 0. 초기 상태
Step 1. Head 값을 Head.next로 변경
탐색
삽입하거나 삭제할 때 head와 tail을 옮겨 줘야 했다.
이건 탐색을 원할하게 하기 위함이다.
단일 연결리스트에서 시작부터 끝을 확실히 정해야 시작점에 해당하는 head 노드 부터 출발해서
tail 노드가 나오기 이전 까지 next를 따라가며 탐색을 진행할 수 있기 때문이다.
'자바 JAVA > 자바 기초' 카테고리의 다른 글
| 자바 for-if문으로 조건을 만족하는 합, 곱 구하기 (0) | 2023.01.29 |
|---|---|
| 자바에서 count 변수로 개수 세기 (0) | 2023.01.29 |
| 자바 함수정의 및 사용하기 (0) | 2023.01.26 |
| 자바(Data Structure) 자료 구조 - 배열 (0) | 2023.01.23 |
| 자바 - Scanner(System.in) 특정 문자를 사이에 두고 입력받기 (0) | 2023.01.23 |

댓글